What's the Deal with Summed-Input Stereo Effects?

Recently, there’s been a lot of controversy about effects that use summed stereo inputs vs. independent inputs. Obviously, nobody wants their stereo signal unintentionally collapsed to mono. So, effects with independent stereo inputs are clearly better, right? How has this gone unnoticed for decades and is only now exposed as a cost-cutting measure to cheat unsuspecting consumers?
Except, that’s not what’s happening here — not even close.
In this blog post, I will explain how stereo effects are designed, why they are designed this way, and the source of confusion around channel summing. I will also explain where channel summing might actually be desirable and where it’s not.
(I apologize in advance for the length of this blog post. This topic is complicated and requires a fair amount of explanation.)
Processing Types
To dispel the confusion around channel summing, we need to first understand some basic concepts about effect processing. Let’s review inline vs. sidechain processing, how each of these are handled in stereo effects, and where channel summing should and should not take place.
Inline Processing
An inline processor performs processing inline — directly on the signal.

That's easy enough.
Stereo Inline Processing
For an inline stereo effect, the processing is performed independently on each channel, left and right. Control parameters may be coupled, so that one control affects both channels. For example, a panning tremolo may use one LFO (low-frequency oscillator) circuit with two phase-locked outputs.
The following diagram shows an inline stereo processor:
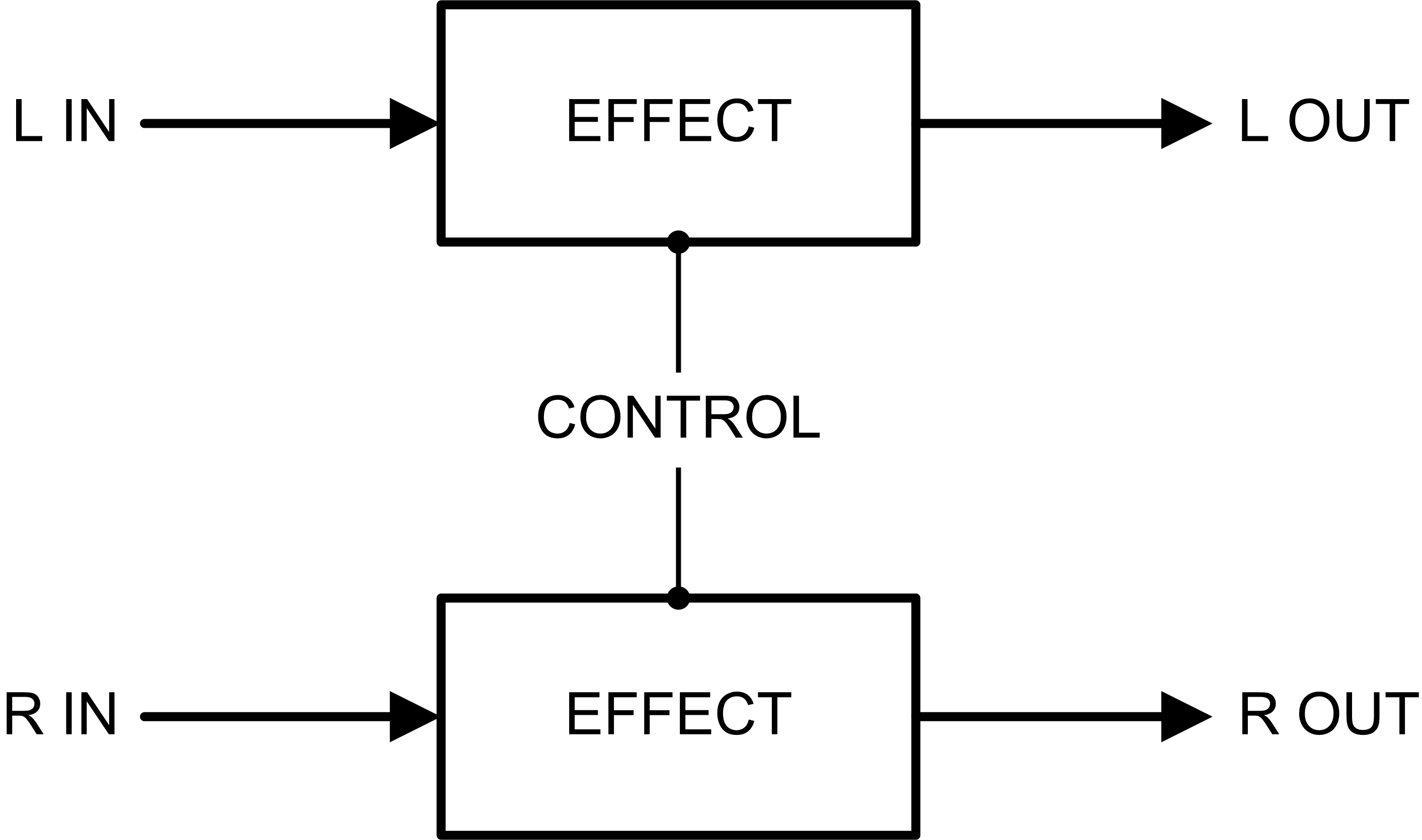
Left and right processors are shown separately, but the effect could be performed by one processor in which the two signal paths remain separate. Examples of inline stereo processors are panning tremolo, rotary speaker and speaker/cabinet emulation.
In this case, summing the input channels before processing would be very bad, as it would collapse any prior stereo image to mono.
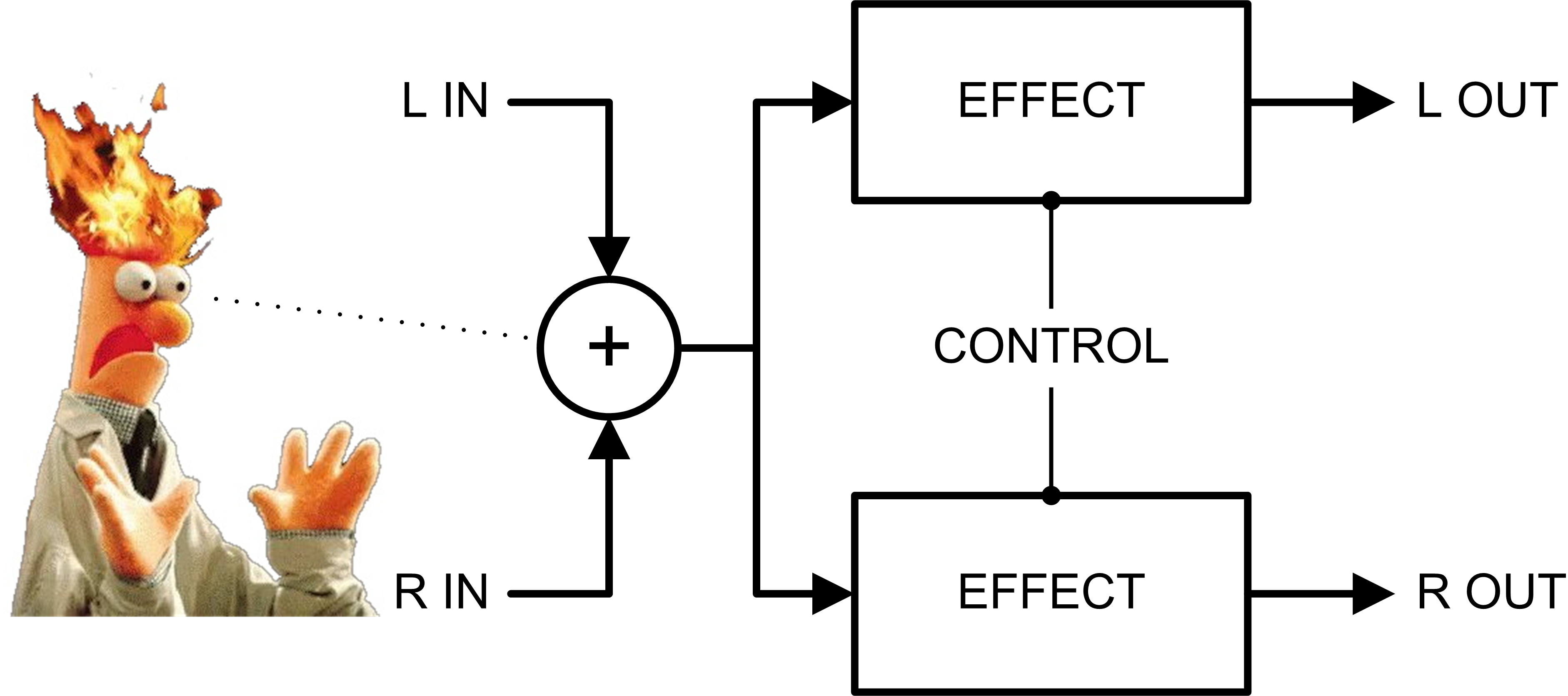
When people read that an effect sums the inputs, this is the image that may be conjured.
However, as I am writing this blog post, I can't recall of any stereo effect processors that are implemented like this. This doesn’t mean that there aren’t any, but I suspect they are rare — it’s hard to keep up with the myriad of effect processors on the market, and I don’t go out of my way to see what everyone else is doing. Please drop me an email if you know (for a fact) of a stereo effect processor that does this.
So, let’s next review the sidechain processor, so we can see where the confusion arises.
Sidechain Processing
A sidechain processor splits the signal into “dry” (unprocessed) and “wet” (processed) signals. The wet signal path is the sidechain, and it is processed to create the effect. The wet signal is added back to the dry signal through a mixer circuit.
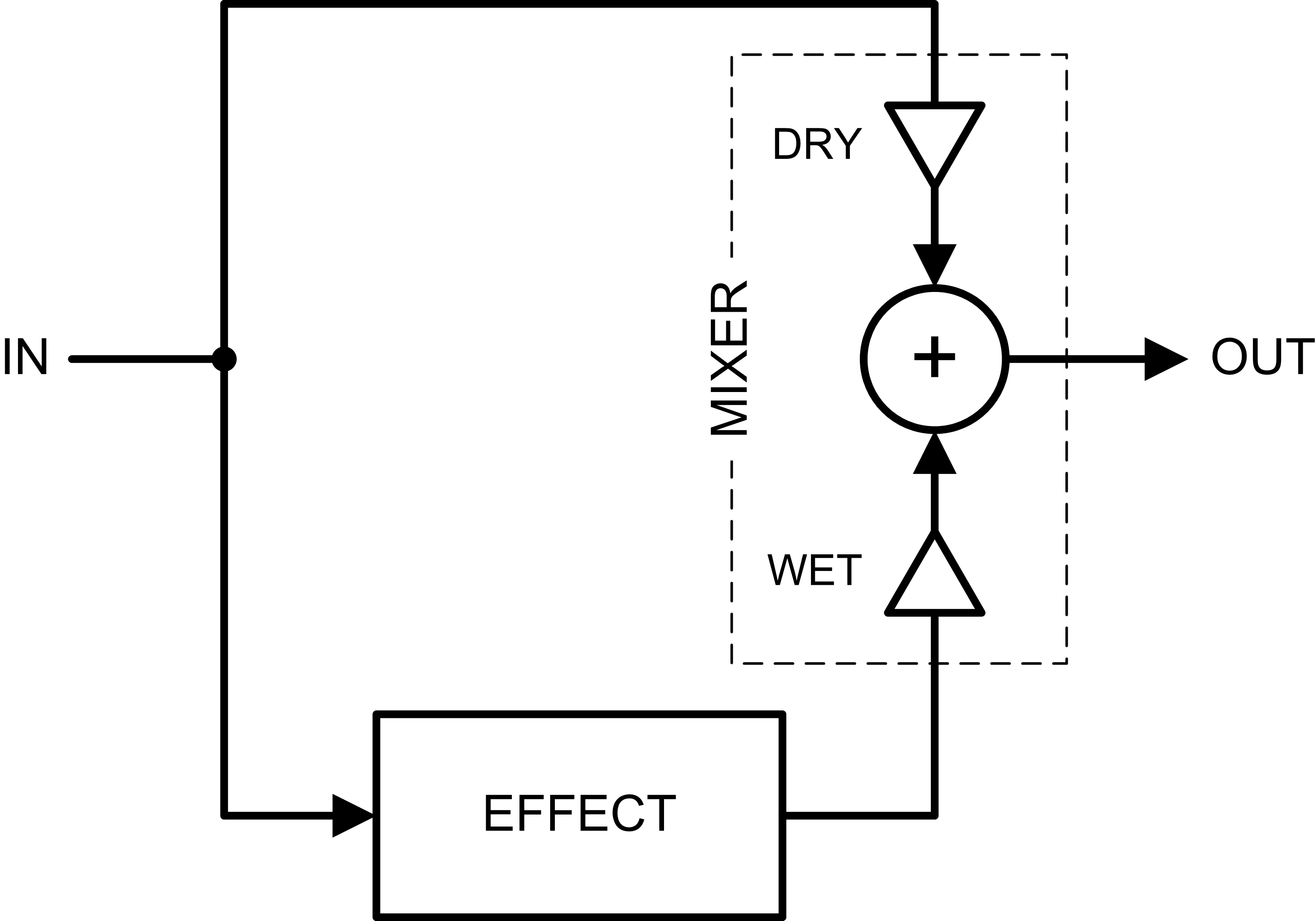
The mixer circuit may allow adjustment of the dry/wet signal levels. A mix knob may adjust both in tandem so that the output level is equivalent to the input level. Examples of side-chain processors are reverb, delay, chorus, flanger and phaser.
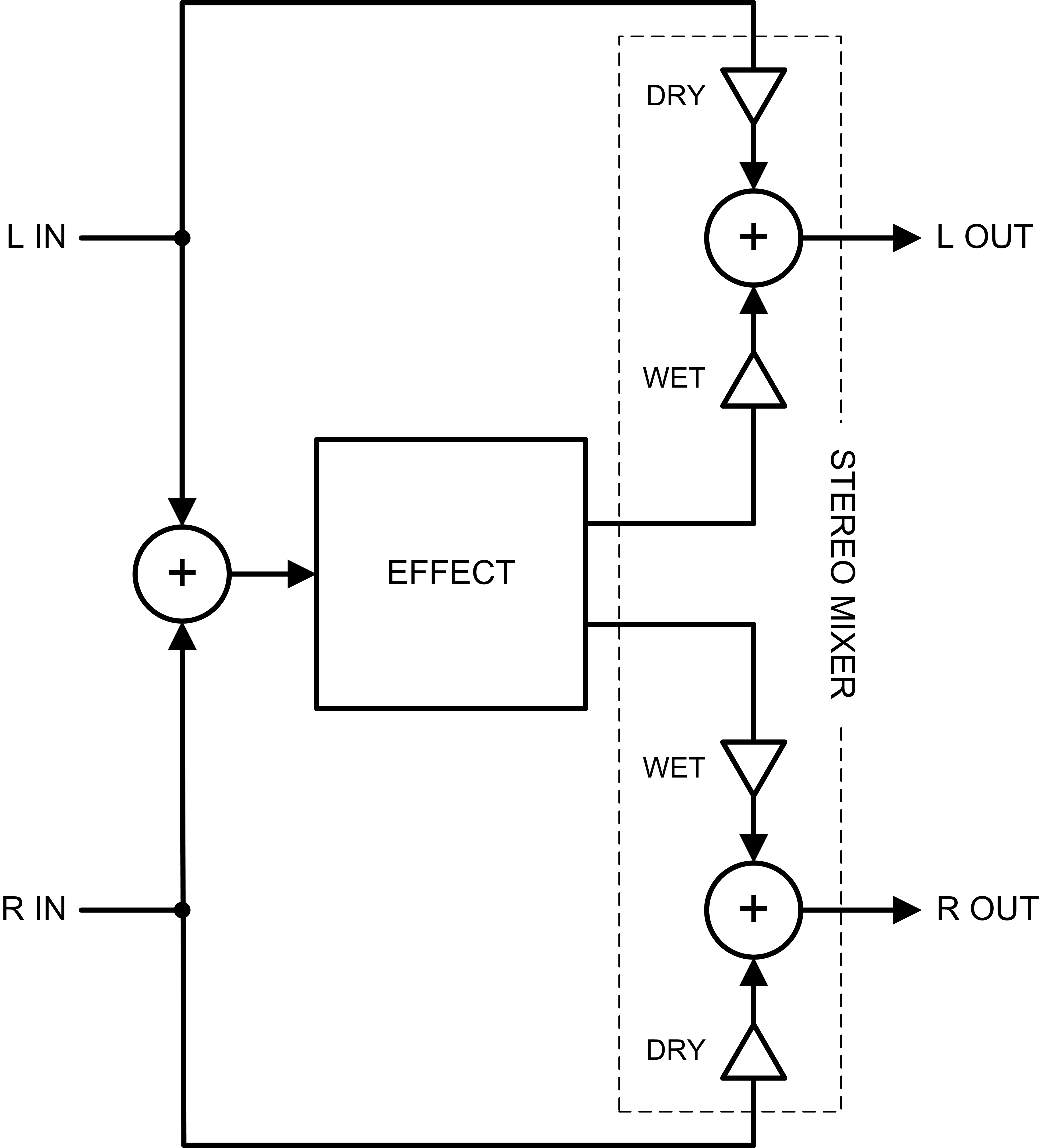
Stereo Sidechain Processing
A stereo sidechain processor looks something like the following, with both the left and right channels split into dry and wet signal paths:
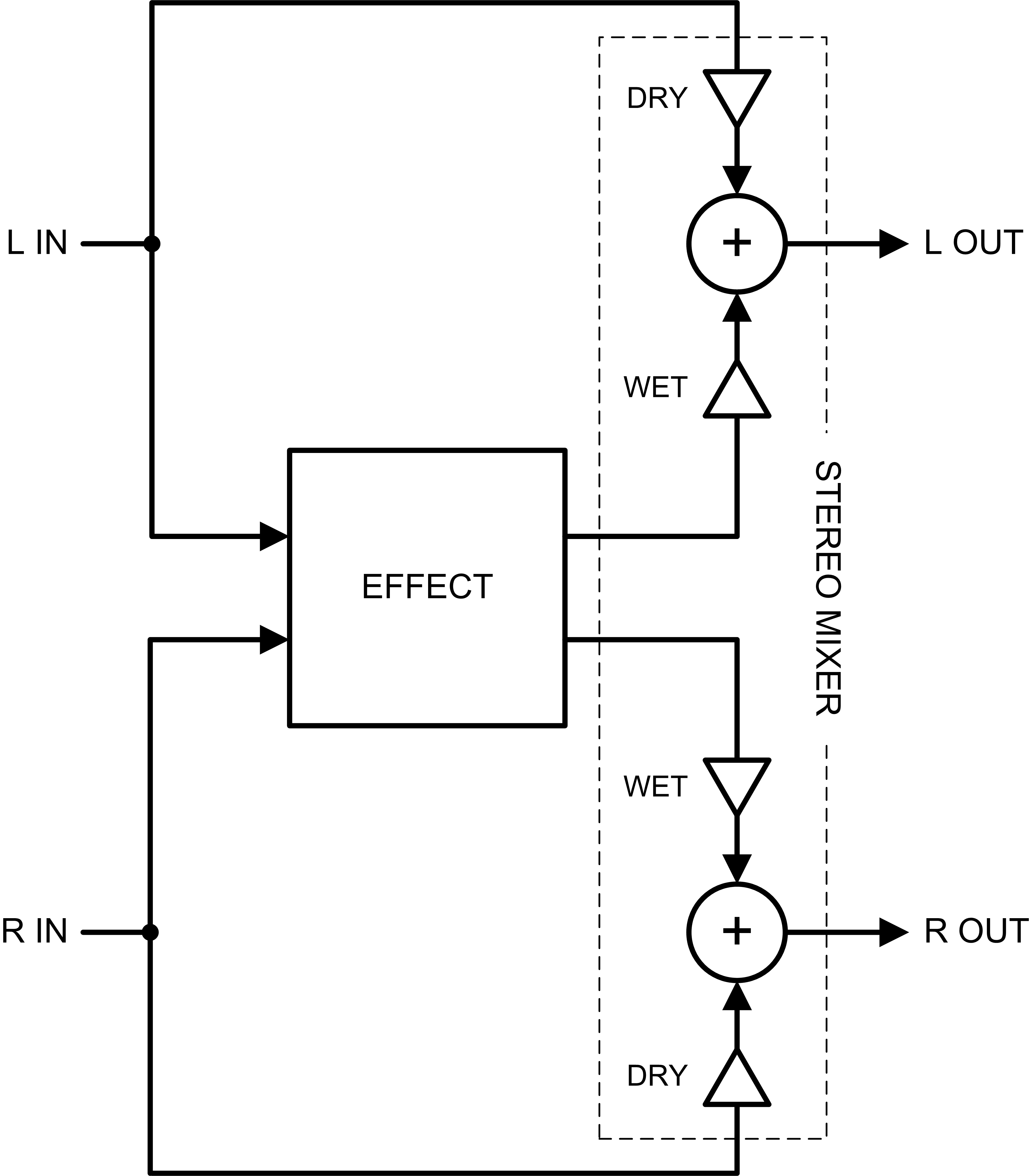
The dry signals remain independent, and both wet signal paths are processed by one processor. Internal to the processor, the signals may remain independent or not, depending on the construction of the algorithm. But should they remain independent in this case? Before we jump to conclusions, let’s explore what a stereo sidechain effect may be trying to accomplish.
Stereo Reverb Example
Let’s look at reverb as an example. Remember that a stereo reverb effect emulates the sound in an acoustic space — this is easily forgotten when you have reverbs that emulate an emulation of an emulation (such as a reverb pedal that emulates a digital rack reverb that emulates a plate reverb).
Acoustic Space with Mono Source
When a single sound source is placed in an acoustic space (a room, concert hall, etc.), a listener will hear both the direct, line-of-sight sound as well as the sound that reflects off of the surfaces in the acoustic environment. The reflected sound continues to bounce around the space until it is completely absorbed by the air or surfaces. The combination of these reflected sounds is reverberation.
The following illustration shows a simplified version of these signals, with the sound source indicated by a speaker and the listener by a circle. The direct sound is shown as the “dry” signal and the reverberation is shown as the “wet” signal:
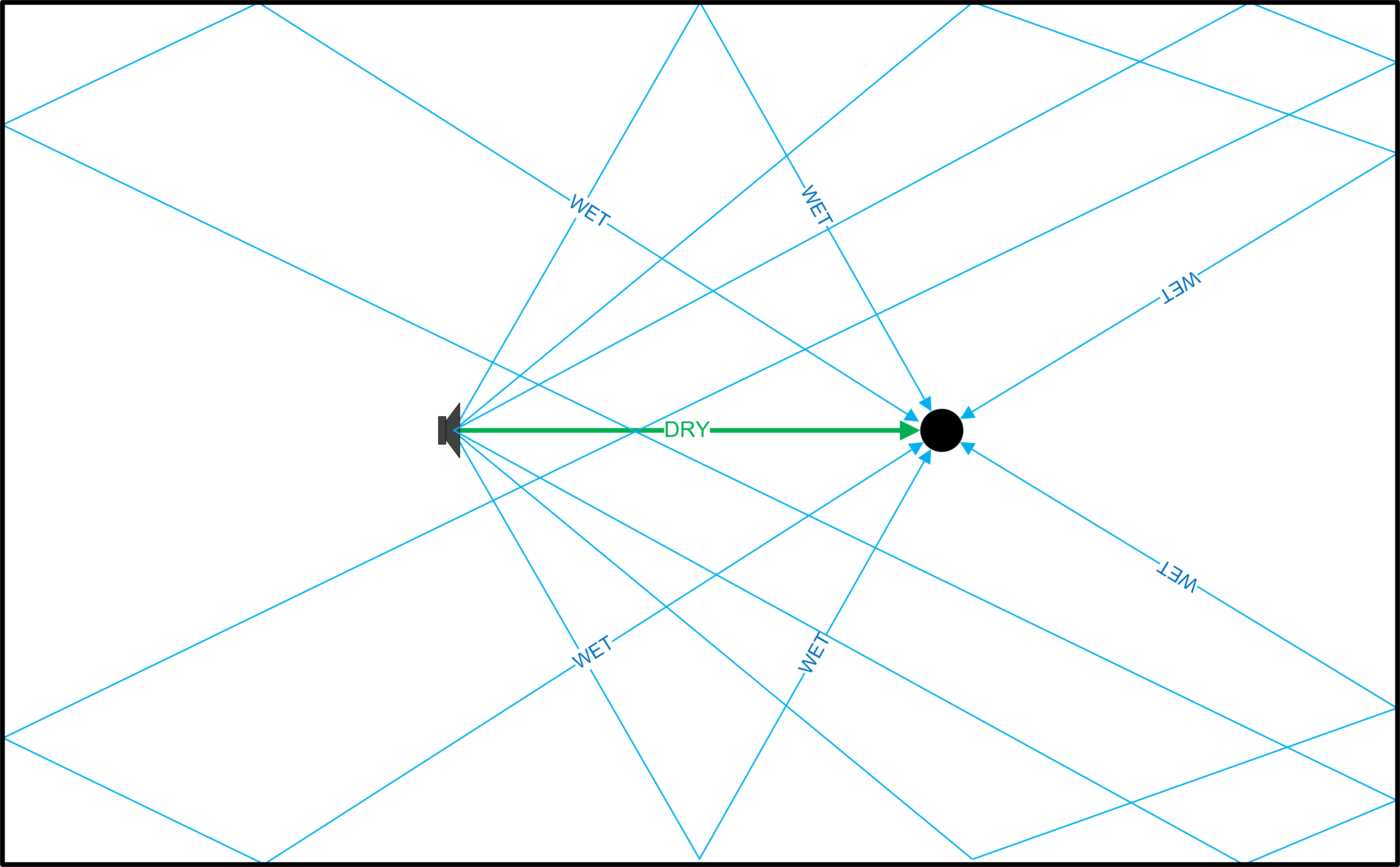
Even though only a few reflections are shown, it is apparent that the reverberation quickly envelops the listener. Regardless of where the source is located, the listener will perceive the reverberation as coming from all sides of the acoustic space.
Acoustic Space with Stereo Source
Now, imagine you have a stereo sound source in the same acoustic space, as illustrated below:
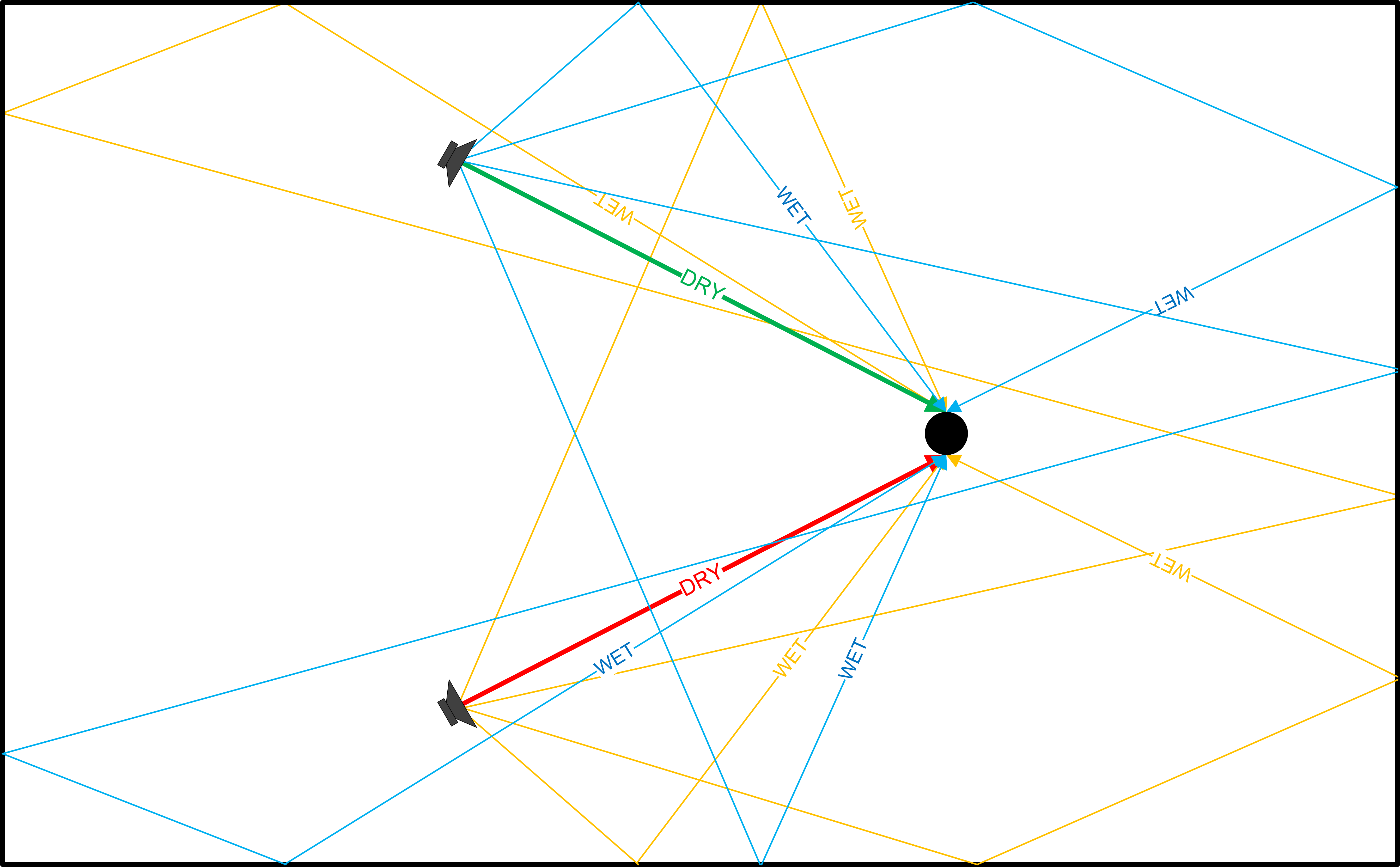
In this example, each source has a direct, line-of-sight sound path to one of the listener’s ears. The listener’s head blocks the sound from the source on the other side. (In reality, high frequencies are readily absorbed by the human head but low frequencies are not. For simplicity, we assume that the sources are spread apart and the human head is a perfect absorber of sound, which also has the benefit of preserving the stereo separation of the source.)
On the other hand, reflections from each source (right=blue, left=orange) quickly disperse and distribute evenly throughout the acoustic space. Reverberant sound is omnipresent (assuming that the listener does not have one ear next to a surface), so a listener will hear each source’s reverberations evenly in both ears. This is not to say that the listener will hear the same sound in both ears; rather, the level of reverberant sound will be the same.
In other words, it doesn’t really matter where the source is located. If we assume that multiple sources are equidistant from the listener, we may simply combine them as one input source. There are different ways to combine these sources, and summing is the simplest and probably the most common method.
Summed-Sidechain Inputs
Summing the sidechain inputs before the effect processor looks something like the following:
The summing node may be internal to the effect processor, or it may be performed externally using analog circuitry. The latter is the source of confusion around “input channel summing.” When a lay person learns that an effect’s sidechain inputs are summed — without the context provided here — he may assume this is bad. Another person may misinterpret this as the stereo inputs (not the sidechains) being summed, which clearly is bad.
We actually want a combined sidechain in this example, but is summing the sidechain inputs the best method? Summing the inputs to a reverb processor has only one drawback: if the stereo inputs are not mono-compatible, the input to the effect processor will cancel out, at least partially. However, all properly-constructed stereo signals should be mono-compatible, so this normally is not an issue. I suggest you read my blog post about why all stereo signals should be mono-compatible.
Other Combined-Sidechain Methods
As I mentioned, summing the sidechain inputs is only one method for handling multiple sources in an acoustic space. While this is the method we use in the Immerse Mk II Reverberator pedal, we do something different in our Wet Reverberator software plug-in. The only advantage to other methods is that they mitigate or eliminate the issues with non-mono-compatible inputs. They aren’t as efficient and don’t separate the sidechain paths (nor does an actual acoustic space). There’s also a bonus to summing the sidechain inputs: it increases the signal-to-noise ratio of the analog-to-digital conversion by 3 dB.
In my opinion, there is no best way to combine inputs to a reverb processor. Whether or not an effect designer chooses to sum the sidechain inputs is mostly a matter of convenience. There really isn’t an audible difference between them except in fringe use cases.
Independent Stereo Sidechains
So why not simply separate the two channels, sidechains and all? In this example, a reverb effect with separate, independent sidechains is analogous to having two separate acoustic spaces, one for each ear. I have illustrated this by inserting a “partition” down the center of the acoustic space — notice that the reflections in each room now remain separate.
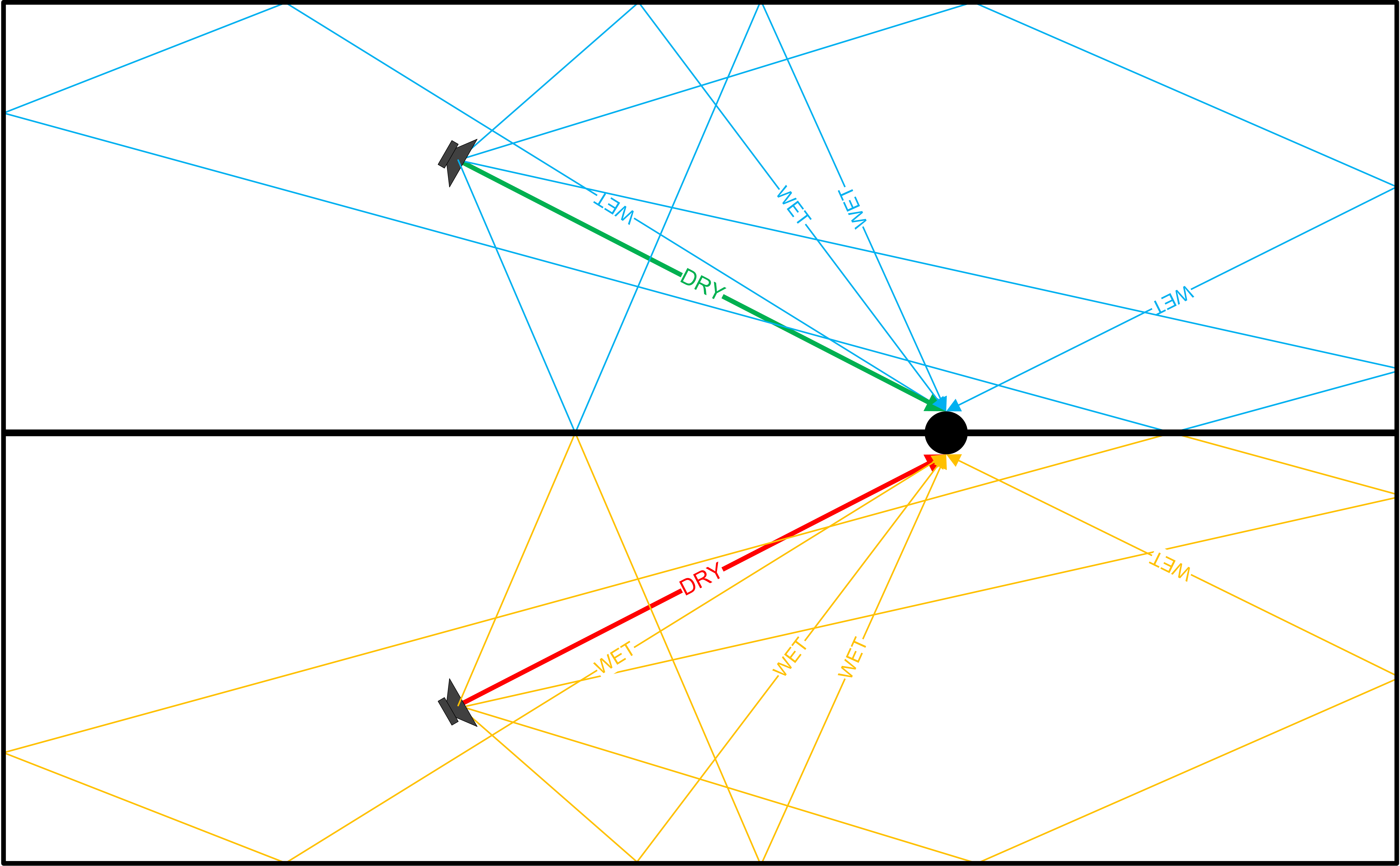
While this is not necessarily wrong, it certainly is not a natural acoustic environment and can yield unexpected results. For example, when panning a stereo signal before an independent-stereo reverb, the reverb will follow the source as it moves side-to-side. When the apparent source is centered, you will hear both reverb channels in stereo; however, when the apparent source is panned to one side, the stereo image will collapse to mono on that side. That is, unless you set the reverb depth (decay) longer than the panning time, in which case you will diminish the stereo panning effect. While this may be an interesting effect, it is not what happens in a natural acoustic space.
Combined vs. Independent Sidechains
Consider that reverberation is often used during the recording process to place separately-recorded tracks in the same acoustic space, creating a more cohesive mix. The same principle applies to a stereo signal: reverberation produced using a combination of the two channels can create cohesiveness.
How does combining the sidechain inputs affect the stereo image of the input signal? The only time you will completely remove any previous effects’ stereo imaging is when the Mix is 100% wet. However, I don’t think this is cause for concern, for the following reasons:
- I don’t recommend that you run effects at 100% wet, except when they are in a sidechain (such as aux send or parallel loop). The dry signal itself adds a layer of sound, which is removed when running 100% wet. Dialing in a little of the dry signal — just enough to blend with the wet signal — will still sound “100% wet.”
- Stereo effects such as reverberation, delay/echo and chorus use decorrelation methods (various changes in time and pitch) to create a stereo image. Reverberation tends to time-smear whatever is put into it, so any differences between the two input channels as a result of decorrelation will be time-smeared beyond recognition. The output still sounds stereo, because the reverb is stereo; but the result will be very similar whether the reverb’s sidechains are combined or independent.
Stereo Effects in General
When deciding whether or not to combine the sidechain inputs of a stereo effect, the effect designer must determine what stereo perception factors are most important.
Stereo using Level Differences
The most rudimentary form of stereo perception is panning a signal from side-to-side. This makes the apparent source sound as if it is moving from one side to the other. The difference between left and right channel levels is one auditory cue that our brains use to infer source position.
Stereo using Time Differences
Sound emitted from a real sound source will traverse different-length paths to a listener’s two ears, which means that it will arrive at one ear slightly later than the other. This time difference is another auditory cue our brains use to infer a source’s position. Effects such as reverberation and chorus rely on this auditory cue to make a sound appear as though it encompasses you, or that it is moving around you, while remaining balanced (equal left/right levels) in the center of the stereo image. We call this an illusion of multi-directional audible perspective, which is created using one or more of the previously-mentioned decorrelation methods.
Level vs. Time Differences for Stereo Sidechain Effects
In some regards, these two auditory cues are mutually exclusive. When a signal is hard-panned to one side, there is no way to create a multi-directional perspective. However, creating a strong multi-directional perspective requires both channels to be approximately equal in level. To use both auditory cues simultaneously, the level difference between the two channels must be limited. Or, hard-panning can be time-limited, such that a reverb or chorus in both channels can follow to create a multi-directional perspective.
If a stereo sidechain effect is implemented with independent sidechains, a hard-panned source will create an effect only on one channel. In other words, the perception of stereo must rely on only the difference in level between the two channels.
On the other hand, if a stereo sidechain effect is implemented with a combined-input sidechain, a hard-panned source will create an effect in both channels. This implementation allows the perception of stereo to use both level difference and multi-directional perspective — the level difference is due to the dry signal, whereas multi-directional perspective is created by the wet signal.
Personally, I find that multi-directional perspective creates a more captivating and less fatiguing stereo illusion than panning or level differences between channels. This is why I favor the use of non-independent sidechain processing in many stereo effects.
Conclusion
Much of the confusion surrounding “summed stereo inputs” arises from the misinterpretation of how processing in a sidechain affects a stereo image. Summing the inputs to the sidechain path has been a common practice since the dawn of digital effect processors. This is not the same as summing the inputs themselves and does not affect the dry, unprocessed signals, which remain independent.
Some effect users are concerned about preserving the integrity of the stereo image at each point in the signal chain. A lay person may intuit that maintaining independent stereo channels is the proper solution; however, this does not necessarily result in the most natural-sounding effect, or an effect with the strongest stereo imaging. In fact, a combined or summed sidechain input often yields a better result.
(Originally posted by Brian Neunaber 05/25/2021)